8b/10b下的编码/加扰和组帧
8b/10b下的编码/加扰和组帧
为了更加清晰明确的表达出协议的意思,一些关键的术语采用英文,在第一次时会给出个人对于该英文的理解和翻译
8b/10b编码
8b/10b编码简介
8b/10b编码是将一个8b的数用10b来表示,其中高三位采用的3b/4b编码,低5位采用的5b/6b编码。8b/10b编码分为控制码编码和数据编码,控制码以kx.y表示,数据码以Dx.y表示,其中x为8比特数低5位的十进制编码,y为8比特数高三位的十进制编码。例如:一个8比特的数据6Ah,二进制表示为0110 1010,高三位为011,十进制表示为3,低五位为01010,十进制表示为10,所以编码前可以用D10.3表示。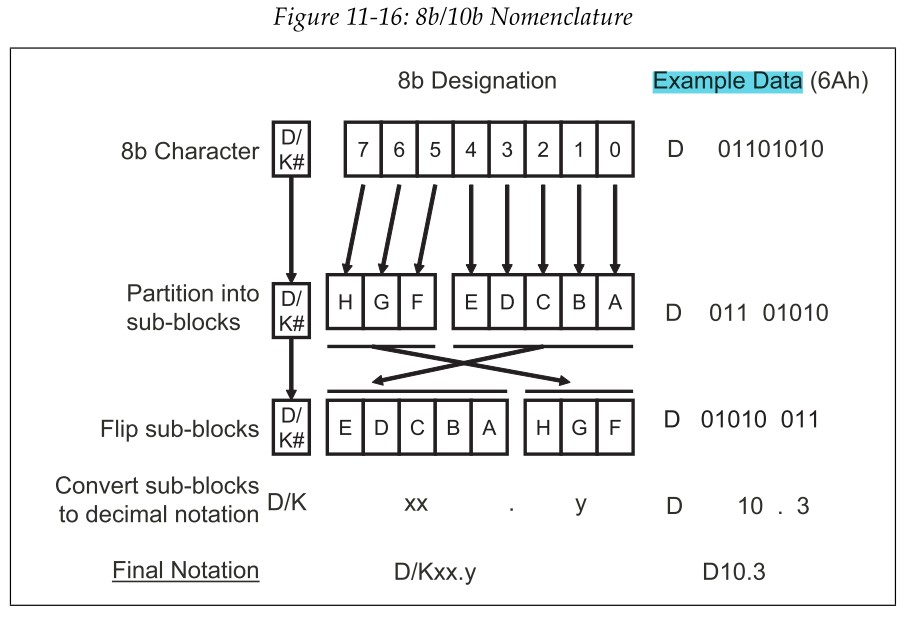
8b/10b编码具有如下的特点:
- 3b/4b编码后的结果不会超过3个0或者3个1
- 5b/6b编码后的结果不会超过4个0或者4个1
- 8b/10b编码后的结果0,1个数差别最多是2个,即10比特的数中只能出现4个0+6个1,5个0加5个1,6个0加4个1三种情况。
- 对数据而言,8b/10b编码后不会出现连续的5个0或者连续的5个1
8b/10b编码规则
- 仅适用于链路速率为2.5GT/s和5.0GT/s
- 编码前后的值可参考pcie 8b/10b编码表
- 12种特殊(COM,STP,SDP,END,EDB,PAD,SKP,FTS,IDL,k28.4,k28.6,EIE)的符号在8b/10b种需要引入一个控制字符,用于表明编码后的数据是一个控制字符而不是数据
- 第一次退出电气空闲时,disparity(失调)的选择
- disparity就是symbol(符号)中0,1个数差异,如果1比0多,就是positive disparity(正失调),0比1多就是negative disparity(负失调)
- 对于发射机而言,在电气空闲之后第一次传输差分数据时,如果没有特殊的要求,发射机允许选择任何disparity,此后发射机必须遵守合适的8b/10b编码规则直到下一次进入电气空闲
- 对于接收机而言,检测到从电气空闲退出后(即收到了对端的数据),接收机的初始disparity被认为是第一个symbol的disparity,第一个symbol用来实现symbol lock(符号锁定)。如果在传输差分信息的过程中,由于一些错误导致symbol lock丢失,在重新实现symbol lock后,Disparity必须重新初始化。在初始化disparity设定好之后,后续所有接受到的symbol必须根据current running disparity(当前运行中的失调)来决定8b/10b解码后的值。running disparity(RD)是根据发送或者接受到Symbol的disparity实时计算得到。
- 如果接受的symbol是在错误的running disparity一列(如Current RD+,但是收到的6Ah为010101 11000b)或者接收到的symbol既不在Current RD+一列也不再Current RD-一列,在Non-Flit模式下,则物理层必须向数据链路层报告接收到的symbol是无效的,并且是一个Receiver Error(接收机错误),该错误必须报告,且跟端口关联。在Flit模式下,symbol发生错误可以通过FEC逻辑纠正,如果在Flit边界发生了8b/10b解码错误或者检测到K码,接收机可以发送任何8比特的值给FEC逻辑。
8b/10编码状态机
- pcie6.2协议无此部分,结合mindshare的个人理解
- 8b/10b在positive disparity和negative disparity下可能编码值不一样
- 初始disparity由发射机决定
- 然后根据当前10比特数据中的0,1个数,决定下一个数据用何种disparity,如果当前发送的数据中0,1个数不等,则下一个数据采用另外一种running disparity一列的数据。如果0,1个数相等,则下一个数据仍然采用当前running disparity这一列的数据
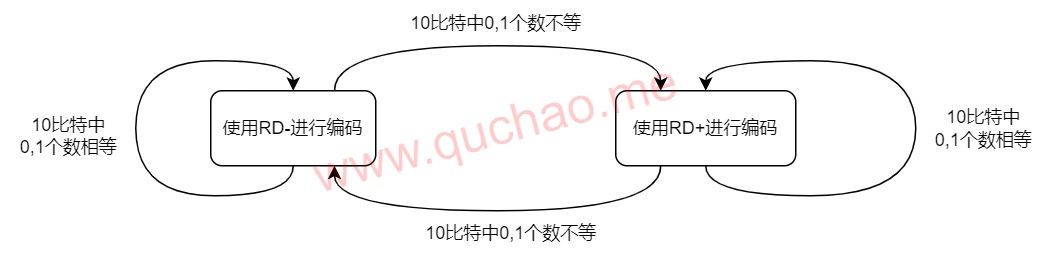
- 刚开始为RD+,下一个采用RD-表明当前发送的数据中0比1多,为了平衡1和0的个数,就需要多发送1,需要发送positive disparity的数。即Current RD+就发negative disparity或neutral disparity(10比特数中0,1个数相等)的数,Current RD-就发送positive disparity或者neutral disparity的数
- 例如:本端发射方向需要发送K28.5(BCh)+K28.5+D10.3(6Ah)时
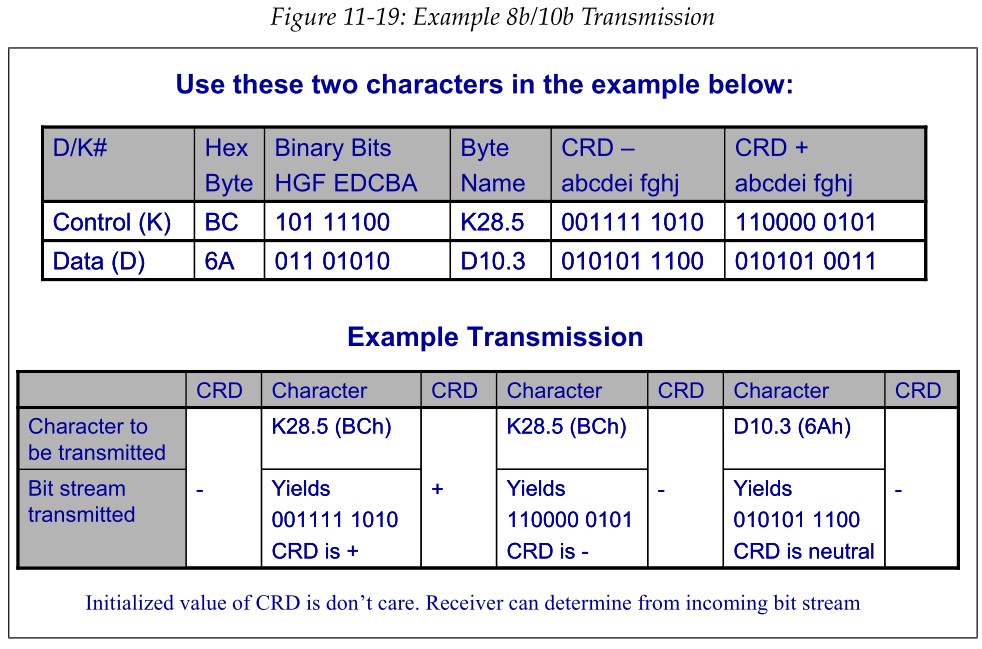
- 本端选择的初始disparity为负,K28.5在Current RD-时的编码为001111 1010b,此时1比0多,为了平衡数据中0和1的个数,就需要多发一些0。
- 下一个数选择Current RD+一列的编码,K28.5在Current RD+一列的数据为110000 0101b,此时0比1多,需要多发些0。
- 但是D10.3在Current RD+和Current RD-的编码中0,1个数都是相等的,依然需要采用Current RD-一列的编码(因为只要0,1个数相等,就一直采用Current RD-一列的编码,直到出现0比1多的情况,而如果采用Curreent RD+一列,不会出现0比1的情况,可能会造成一直在积累1),其值为010101 1100,此时0,1个数相等。
- 下一个需发送的数仍然采用RD+一列的编码。
- 例如对端接受方向
- 首先收到001111 1010b,此时1比0多,初始disparity为正,但是只有COM字符在8b/10b编码才可能出现连续5个0或者连续5个1,所以此处8b/10b应该可以解码出来为BC(Current RD+和Current RD-两列的编码是互补的,即加起来为11111 1111b)。下一个数采用Current RD+一列的编码
- 下一个收到的数为110000 0101b,采用Current RD+一列的编码,解码的结果为BCh,此时0比1多,下一个数采用Current RD-一列的编码结果
- 接着收到010101 1100b,该值在Current RD-一列解码出来的值为6A。此时0,1个数相等,下一个数仍然采用Current RD-一列的结果
- MISC
- Q. 既然接受方向是根据第一个symbol的disparity来作为初始disparity的,那会出现收到的第一个symbol中0,1个数相同的情况吗?
- A. 这个地方理论上是不会发生的,因为8b/10b编码中发送的第一个symbol总是COM(K28.5)字符,而COM字符在Current RD-和Current RD+时的编码都0,1的个数都不相等,所以接收方从理论上而言总是可以计算出来一个初始的disparity。
- Q. 接受端初始的disparity error跟发送端不一致,算receiver error吗?
- A. 这个地方我觉得不应算,因为协议描述的是接受到的symbol不在正确的running disparity一列时才是receiver error,初始的disparity是根据收到的symbol来确定的,跟running disparity并没有关系,只有后面收到的symbol才会跟running disparity进行对比。
- Q. 既然接受方向是根据第一个symbol的disparity来作为初始disparity的,那会出现收到的第一个symbol中0,1个数相同的情况吗?
8b/10b编码作用
- 维持直流平衡
- 最重要的作用。尽可能保持一端时间内0和1的个数基本一致。如果在接收端出现长0或者长1,会影响接收端对0,1的判断。比如接受端一端时间都是收到的0,然后突然来一个1,接着又是0,由于本端的RX跟对端的TX之间存在耦合电容,长时间的0会被认为存在一定的直流分量,被耦合电容滤掉,然后出现1时,又出现0时,对电容来不及充电,导致RX端电压达不到电平1的标准,出现误识别位0。
- 提高纠错能力
- 8b可以表示256种情况,而10b有1024种可能。如果一个10b的数不在8b/10b编码表中,那就产生一个decode error来表明链路中出现了这种错误。
- 将时钟方便的嵌入到数据中
- 因为8b/10b编码中0和1的跳变比较频繁,方便CDR电路将时钟恢复出来,0,1跳变越频繁越容易恢复出来时钟。
8b/10b编码中的一些控制码(K Codes)
- 又叫k码
- 作用
- 用于lane和link的初始化和管理
- 在Non-Flit模式下(pcie6.0新增),让DLLPs和TLPs组成帧(frame),方便快速区分这两种类型的包。比如8b/10b编码,TLP以STP(K27.7)开头,DLLP以SDP(K28.2)开头
- 12种特殊的控制码
| 编码 | 符号 | 全称 | 16进制表示 | 二进制(Current RD-) | 二进制(Current RD+) | 描述 |
|---|---|---|---|---|---|---|
| K28.5 | COM | Comma | BC | 001111 1010 | 110000 0101 | 用于lane和link初始化和管理 |
| K27.7 | STP | Start TLP | FB | 110110 1000 | 001001 0111 | Non-Flit模式:表示TLP包的开始,Flit模式:保留 |
| k28.2 | SDP | Start DLLP | 5C | 001111 0101 | 110000 1010 | Non-Flit模式:表示DLLP包的开始,Flit模式:保留 |
| K29.7 | END | End | FD | 101110 1000 | 010001 0111 | Non-Flit模式:表示TLP包或者DLLP包的结束,Flit模式:保留 |
| k30.7 | EDB | End Bad | FE | 011110 1000 | 100001 0111 | Non-Flit模式:表示无效TLP包的结束,Flit模式:保留 |
| k23.7 | PAD | Pad | F7 | 111010 1000 | 000101 0111 | 在Non-Flit模式用于组成帧,在Non-Flit模式和Flit模式下用于链路宽度和lane顺序的协商 |
| k28.0 | SKP | Skip | 1C | 001111 0100 | 110000 1011 | 当两个通信端口的比特率不同时,用于补偿两端的差异,在Flit模式和Non-Flit模式下用法相同 |
| K28.1 | FTS | Fast Trainng Sequence | 3C | 001111 1001 | 110000 0110 | Non-Flit模式,用于组成FTSOS,从L0s退出到L0时,用于快速实现符号锁定(symbol lock) |
| K28.3 | IDL | Idle | 7C | 001111 0011 | 110000 1100 | 用于组成EIOS,Flit模式和Non-Flit模式下用法相同 |
| K28.4 | 9C | 001111 0010 | 110000 1101 | 保留 | ||
| K28.6 | DC | 001111 0110 | 110000 1001 | 保留 | ||
| K28.7 | EIE | Electrical Idle Exit | FC | 001111 1000 | 110000 0111 | 2.5GT/s下保留,用于组成EIEOS,并且要先于FTS发送 |
Frame(组帧)
Lane上可以传输两种类型的frame(帧),第一类由OS((Ordered Sets,有序集,简称OS)组成;第二类在数据流中,由TLPs和DLLPs组成。有序集在每条lane上都会持续的发,因此如果一个link由多条lane构成,完整的有序集会同时出现所有lane上。Flit模式下没有framing相关的错误,因为Flit模式下可以通过FEC纠错。
Non-Flit模式下的数据流
- Framing机制采用特殊的symbol来管理TLP和DLLP,用K28.2(SDP)来表明将要传输DLLP,用K27.7(STP)来表明将要传输TLP,用K29.7(END)表明TLP或者DLLP的结束。
- 当没有包信息或者特殊的OS需要传输时,发射机处于逻辑空闲(Logical Idle)状态
- 发射机处于逻辑空闲状态时,必须发Idle Data(空闲数据,由00h组成),Idle Data也需要经过加扰和编码
- TLP和DLLP中的Data symbol需要经过加扰和编码
- 当接收机没有收到包或者特殊的OS时,接收机也是处于Logical Idle(逻辑空闲)状态,并且也应该接受Idle Data
- 在传输Idle Data期间,SKPOS也必须按照一定的规则持续传输
Framing规则
接收机可以检查下列规则(都是独立检查,并且是可选),如果接收机检查了,违反后会产生Receiver Error,并且上报错误时会关联到port。规则如下:
- TLPs组成Framed必须要把STP符号放在TLP的开始,并且要把END符号或者EDB符号放在TLP的结束
- 在STP和END或者EDB symbol之间,TLP最少包含18个symbol.如果接收到的序列,STP和END或者EDB符号之间的符号数小于18个,接收机允许将这视为一个Receiver Error(可选的功能,如果检查了则必须跟port关联起来)
- DLLPs组成Frame必须要把SDP symbol放在DLLP的开头,并且把END symbol放在DLLP的末尾
- 当没有TLPs,DLLPs或者特殊的symbol需要发送或者接受时,这时的一个或者多个symbol time(符号时间)成为logical Idle,logical Idle需要发送和接受空闲数据(00h)
- 当发射机处于逻辑空闲时,Idle data符号应该在所有lane上都传输,Idle data会被加扰(避免差分线上出现长的0)
- 接收机必须忽略接收到的Idle data,并且不得依赖这些数据,除了一些加扰过的特定数据序列外(比如物理层的状态机在Configuration.Idle和Recovery.Idle需要判断收到的Idle data个数,这时就会依赖Idle data)
- 如果链路宽度大于x1,当从Logical Idle准备开始传输TLP时,STP符号必须放在lane0上
- 如果链路宽度大于x1,当从Logical Idle准备开始传输DLLP时,SDP符号必须放在lane0
- 一个symbol time内,STP symbol只能放在链路上一次
- 一个symbol time内,SDP symbol只能放在链路上一次
- 在相同的符号时间,链路上可以出现一个STP符号和SDP符号(eg. x16 SDP(1symbol)+DLLP(6symbol)+END+STP+…)
- 链路宽带大于x4时,STP和SDP symbol可以放在4*N(N是正整数),eg. x8的链路,STP和SDP symbol可以放在lane 0和lane 4,x16的链路,STP和SDP symbol可以放在lane0,4,8和12
- xN(N>=8)的链路,如果END和EDB symbol放在lane k上,K不等于N-1,并且lane k+1没有跟STP symbol或者SDP symbol时(比如没有TLP或者DLLP需要发送时),必须在lane k+1到lane N-1上填充PAD
- eg. x8的链路,END symbol或者EDB symbol放在lane3,当后面没有STP或者SDP symbol时,lane 4到lane 7必须用PAD填充
x4的例子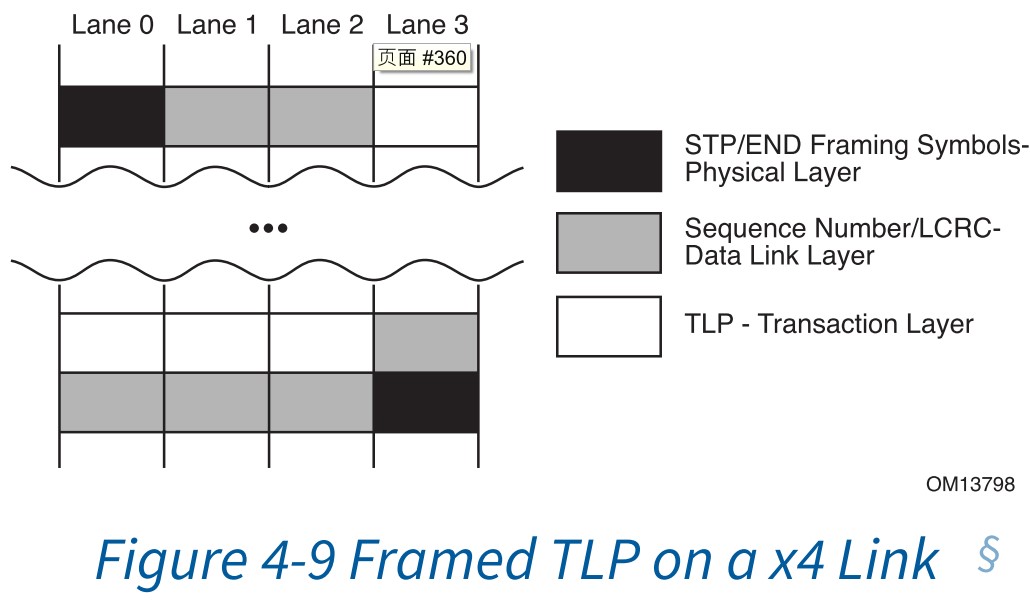
加扰
8b/10b加扰简介
加扰(scrambling)就是将数据流与特定模式序列(pattern)进行异或操作(XOR),使其发送出去的数据变得伪随机,特定模式序列用LFSR(Linear Feedback Shift Register,线性反馈移位寄存器)产生。gen1/2 LFSR的加扰多项式为G(x)=x16+x5+x4+X3+1。对于给定的初始值,LFSR后面的值都是确定的。gen1/2加扰电路如下图所示: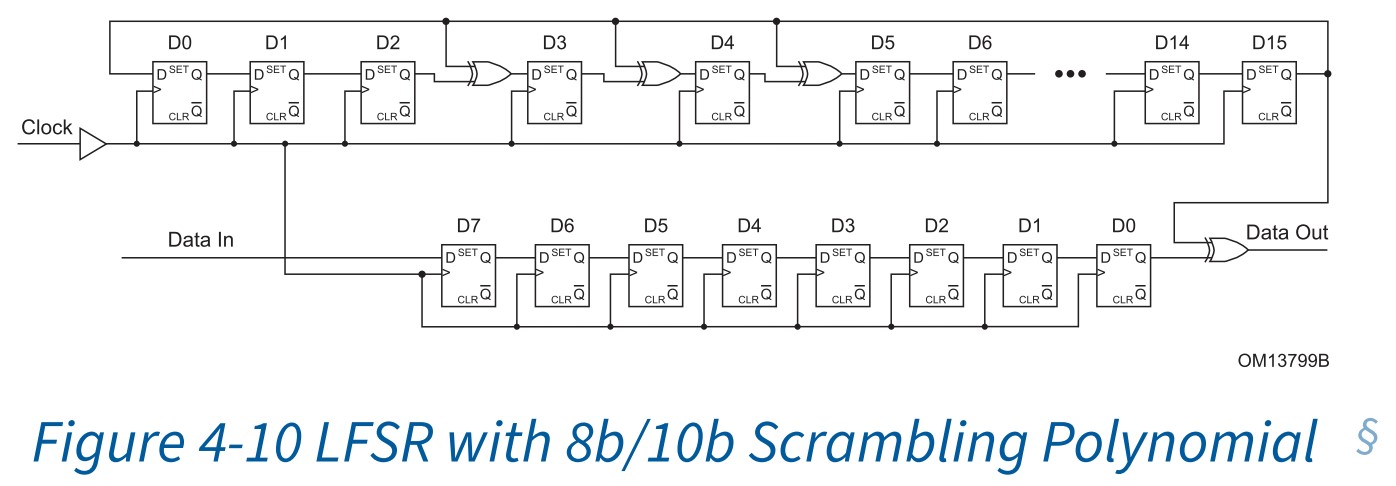
该电路是pcie spec给出的,实际不一定会采用这种,因为这种完成一个symbol的计算需要8个时钟周期。能保证最终实现的效果跟这个电路一致就可以。这里的Dx指的是D触发器,评论区的说法可能不是很严谨。具体加扰步骤如下:
- LFSR中D触发器D15的输出与数据端D触发器D0(数据的比特0)的输出进行异或
- LFSR和数据寄存器串行前进
- 对数据的其它比特也按照数据比特0的方式重复操作
- 可以简单得理解加扰后的数据为输入数据与LFSR输出D8-D15相异或,第一个symbol与D8-D15相异或,
第二个symbol与D7-D0相异或第二个symbol与D0-D7经过组合逻辑后的值相异或(因为D触发器D8-D14只是单纯的移位,没有经过组合逻辑,所以第一个symbol相当于与D8-D15相异或)
8b/10b编码和加扰顺序
- 发射端:先加扰然后在进行8b/10b编码
- 因为8b/10b编码可以保证直流平衡,如果是先编码,在加扰可能会导致0和1的个数相差较大
- 接收端:先8b/10b解码然后在进行解扰(de-scramble)
8b/10b加扰规则
- LFSR相关
- LFSR的初始种子(即D0-D15的值)是FFFFh
- COM 符号初始化 LFSR
- COM字符发送出去之后,发送端的LFSR立即初始化
- link上某条lane收到COM符号后,立刻初始化该条lane的LFSR
- 除SKP外的每一个symbol,LFRS都是串行移位,每个symbol移动8次
- 多lane的link,加扰多项式可以用一个或者多个LFSR实现
- 发送端,如果link上有多个LFSR,它们必须协同工作, 每个LFSR中都要维持相同的同步值(lane与lane之间的输出skew(偏移))
- 接收端,如果link上有多个LFSR时,它们必须协同工作,每个线性反馈移位寄存器需要维持相同的同步值(lane与lane之间的skew)
- 是否需要加扰
- Flit模式和Non-Flit都需要加扰
- 除了有序集(eg.TS1,TS2,EIEOS)中数据、Compliance Pattern(合规性模式序列)和Modified Compliance Pattern(修改过的合规性测试序列)外的所有的数据symbol(D Codes)都需要加扰
- 所有特殊symbol(K 码)不需要加扰
- 是否使能加扰
- 只有在Configuration状态结束后才可以禁止加扰
- Loopback Follower不使用加扰
- 在Detect状态默认使能加扰
- 数据链路层可以通知物理层禁止加扰,具体实现方式协议没做说明,比如设置寄存器禁止加扰
8b/10b加扰代码参考
来源于pcie6.2 附录C
q(D0)表示D触发器初始的输出,首先需要确定当前D15的输出是多少,当前D15输出取决于上一时刻D15的输入
| LFSR移动次数(时钟周期) | D0输入(当前D15的输出) | D0输出 | D1输入(当前D0的输出) | D1输出 | D2输入(当前D1的输出) | D2输出 | D3输入(当前时刻D2输出异或当前时刻D15输出) | D3输出 | D4输入(当前时刻D3输出异或当前时刻D15输出) | D4输出 | D5输入(当前时刻D4输出异或当前时刻D15输出) | D5输出 | D6输入(当前D5的输出) | D6输出 | D7输入(当前D6的输出) | D7输出 | D8输入(当前D7的输出) | D8输出 | D9输入(当前D8的输出) | D9输出 | D10输入(当前D9的输出) | D10输出 | D11输入(当前D10的输出) | D11输出 | D12输入(当前D11的输出) | D12输出 | D13输入(当前D12的输出) | D13输出 | D14输入(当前D13的输出) | D14输出 | D15输入(当前D14的输出) | D15输出 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | q(D15) | q(D0) | q(D0) | q(D1) | q(D1) | q(D2) | q(D2)^q(D15) | q(D3) | q(D3)^q(D15) | q(D4) | q(D4)^q(D15) | q(D5) | q(D5) | q(D6) | q(D6) | q(D7) | q(D7) | q(D8) | q(D8) | q(D9) | q(D9) | q(D10) | q(D10) | q(D11) | q(D11) | q(D12) | q(D12) | q(D13) | q(D13) | q(D14) | q(D14) | q(D15) |
| 1 | q(D14) | q(D15) | q(D15) | q(D0) | q(D0) | q(D1) | q(D1)^q(D14) | q(D2)^q(D15) | q(D2)^q(D15)^q(D14) | q(D3)^q(D15) | q(D3)^q(D15)^q(14) | q(D4)^q(D15) | q(D4)^q(D15) | q(D5) | q(D5) | q(D6) | q(D6) | q(D7) | q(D7) | q(8) | q(D8) | q(9) | q(D9) | q(10) | q(D10) | q(11) | q(D11) | q(12) | q(D12) | q(13) | q(D13) | q(D14) |
| 2 | q(D13) | q(D14) | q(D14) | q(D15) | q(D15) | q(D0) | q(D0)^q(D13) | q(D1)^q(D14) | q(D1)^q(D14)^q(D13) | q(D2)^q(D15)^q(D14) | q(D2)^q(D15)^q(D14)^q(D13) | q(D3)^q(D15)^q(D14) | q(D3)^q(D15)^q(D14) | q(D4)^q(D15) | q(D4)^q(D15) | q(D5) | q(D5) | q(D6) | q(D6) | q(D7) | q(D7) | q(D9) | q(D8) | q(D9) | q(D9) | q(D10) | q(D10) | q(D11) | q(D11) | q(D12) | q(D12) | q(D13) |
| 3 | q(D12) | q(D13) | q(D13) | q(D14) | q(D14) | q(D15) | q(D15)^q(D12) | q(D0)^q(D13) | q(D0)^q(D13)^q(D12) | q(D1)^q(D14)^(D13) | q(D1)^q(D14)^q(D13)^q(D12) | q(D2)^q(D15)^q(D14)^q(D13) | q(D2)^q(D15)^q(D14)^q(D13) | q(D3)^q(D15)^q(D14) | q(D3)^q(D15)^q(D14) | q(D4)^q(D15) | q(D4)^q(D15) | q(D5) | q(D5) | q(D6) | q(D6) | q(D7) | q(D7) | q(D8) | q(D8) | q(D9) | q(D9) | q(D10) | q(D10) | q(D11) | q(D11) | q(D12) |
| 4 | q(D11) | q(D12) | q(D12) | q(D13) | q(D13) | q(D14) | q(D14)^q(D11) | q(D15)^q(D12) | q(D15)^q(D12)^q(D11) | q(D0)^q(D13)^q(D12) | q(D0)^q(D13)^q(D12)^q(D11) | q(D1)^q(D14)^q(D13)^q(D12) | q(D1)^q(D14)^q(D13)^q(D12) | q(D2)^q(D15)^q(D14)^q(D13) | q(D2)^q(D15)^q(D14)^q(D13) | q(D3)^q(D15)^q(D14) | q(D3)^q(D15)^q(D14) | q(D4)^q(D15) | q(D4)^q(D15) | q(D5) | q(D5) | q(D6) | q(D6) | q(D7) | q(D7) | q(D8) | q(D8) | q(D9) | q(D9) | q(D10) | q(D10) | q(D11) |
| 5 | q(D10) | q(D11) | q(D11) | q(D12) | q(D12) | q(D13) | q(D13)^q(D10) | q(D14)^q(D11) | q(D14)^q(D11)^q(D10)) | q(D15)^q(D12)^q(D11) | q(D15)^q(D12)^q(D11)^q(D10) | q(D0)^q(D13)^q(D12)^q(D11) | q(D0)^q(D13)^q(D12)^q(D11) | q(D1)^q(D14)^q(D13)^q(D12) | q(D1)^q(D14)^q(D13)^q(D12) | q(D2)^q(D15)^q(D14)^q(D13) | q(D2)^q(D15)^q(D14)^q(D13) | q(D3)^q(D15)^q(D14) | q(D3)^q(D15)^q(D14) | q(D4)^q(D15) | q(D4)^q(D15) | q(D5) | q(D5) | q(D6) | q(D6) | q(D7) | q(D7) | q(D8) | q(D8) | q(D9) | q(D9) | q(D10) |
| 6 | q(D9) | q(D10) | q(D10) | q(D11) | q(D11) | q(D12) | q(D12)^q(D9) | q(D13)^q(D10) | q(D13)^q(D10)^q(D9) | q(D14)^q(D11)^q(D10) | q(D14)^q(D11)^q(D10)^q(D9) | q(D15)^q(D12)^q(D11)^q(D10) | q(D15)^q(D12)^q(D11)^q(D10) | q(D0)^q(D13)^q(D12)^q(D11) | q(D0)^q(D13)^q(D12)^q(D11) | q(D1)^a(D14)^q(D13)^q(D12) | q(D1)^a(D14)^q(D13)^q(D12) | q(D2)^q(D15)^q(D14)^q(D13) | q(D2)^q(D15)^q(D14)^q(D13) | q(D3)^q(D15)^q(D14) | q(D3)^q(D15)^q(D14) | q(D4)^q(D15) | q(D4)^q(D15) | Q(D5) | q(D5) | q(D6) | q(D6) | q(D7) | q(D7) | q(D8) | q(D8) | q(D9) |
| 7 | q(D8) | q(D9) | q(D9) | q(D10) | q(D10) | q(D11) | q(D11)^q(D8) | q(D12)^q(D9) | q(D12)^q(D9)^q(D8) | q(D13)^q(D10)^q(D9) | q(D13)^q(D10)^q(D9)^q(D8) | q(D14)^q(D11)^q(D10)^q(D9) | q(D14)^q(D11)^q(D10)^q(D9) | q(D15)^q(D12)^q(D11)^q(D10) | q(D15)^q(D12)^q(D11)^q(D10) | q(D0)^q(D13)^q(D12)^q(D11) | q(D0)^q(D13)^q(D12)^q(D11) | q(D1)^q(D14)^q(D13)^q(D12) | q(D1)^q(D14)^q(D13)^q(D12) | q(D2)^q(D15)^q(D14)^q(D13) | q(D2)^q(D15)^q(D14)^q(D13) | q(D3)^q(D15)^q(D14) | q(D3)^q(D15)^q(D14) | q(D4)^q(D15) | q(D4)^q(D15) | q(D5) | q(D5) | q(D6) | q(D6) | q(D7) | q(D7) | q(D8) |
| 8 | q(D7) | q(D8) | q(D8) | q(D9) | q(D9) | q(D10) | q(D10)^q(D7) | q(D11)^q(D8) | q(D11)^q(D8)^q(D7) | q(D12)^q(D9)^q(D8) | q(D12)^q(D9)^q(D8)^q(D7) | q(D13)^q(D10)^q(D9)^q(D8) | q(D13)^q(D10)^q(D9)^q(D8) | q(D14)^q(D11)^q(D10)^q(D9) | q(D14)^q(D11)^q(D10)^q(D9) | q(D15)^q(D12)^q(D11)^q(D10) | q(D15)^q(D12)^q(D11)^q(D10) | q(D0)^q(D13)^q(D12)^q(D11) | q(D0)^q(D13)^q(D12)^q(D11) | q(D1)^q(D14)^q(D13)^q(D12) | q(D1)^q(D14)^q(D13)^q(D12) | q(D2)^q(D15)^q(D14)^q(D13) | q(D2)^q(D15)^q(D14)^q(D13) | q(D3)^q(D15)^q(D14) | q(D3)^q(D15)^q(D14) | q(D4)^q(D15) | q(D4)^q(D15) | q(D5) | q(D5) | q(D6) | q(D6) | q(D7) |
int unscramble_byte(int inbyte)
{
static int descrambit[8];
static int bit[16];
static int bit_out[16];
static unsigned short lfsr = 0xffff;
int outbyte,i;
if (inbyte == COMMA)
{
lfsr = 0xffff; // COM初始化LFRS
return (COMMA);
}
if (inbyte == SKIP) // SKIP不会使LFSR变化
{
return {SKIP};
}
for (i=0; i<16; i++) // 将LFSR的输出转化为数组, bit[15]表示D触发器D15 Q端的值
{
bit[i] = (lsfr >> i) & 1;
}
for (i=0; i<8; i++) // 将需要加扰的数转化为数组
{
descrambit[i] = (inbyte >>i) & 1;
}
// K码跳过加扰,如果是K码,用单独的一比特来表示,比特[8]为1,1&1 = 1,取反为假,表示跳过加扰
if (!(inbyte & 0x100) &&
!(TrainingSequence == TRUE) )
{
descrambit[0] ^= bit[15]; // 数据的比特0与LFSR比特15相异或
descrambit[1] ^= bit[14]; // 数据的比特1与LFSR比特14相异或
descrambit[2] ^= bit[13]; // 数据的比特2与LFSR比特13相异或
descrambit[3] ^= bit[12]; // 数据的比特3与LFSR比特12相异或
descrambit[4] ^= bit[11]; // 数据的比特4与LFSR比特11相异或
descrambit[5] ^= bit[10]; // 数据的比特5与LFSR比特10相异或
descrambit[6] ^= bit[ 9]; // 数据的比特6与LFSR比特9相异或
descrambit[7] ^= bit[ 8]; // 数据的比特7与LFSR比特8相异或
}
// 数据与LFSR异或完成后,整体移动8次
// LFSR 移动8次后,第n个D触发器的输出,见上一个表格的分析
bit_out[ 0] = bit[ 8];
bit_out[ 1] = bit[ 9];
bit_out[ 2] = bit[10];
bit_out[ 3] = bit[11] ^ bit[ 8];
bit_out[ 4] = bit[12] ^ bit[ 9] ^ bit[ 8];
bit_out[ 5] = bit[13] ^ bit[10] ^ bit[ 9] ^ bit[ 8];
bit_out[ 6] = bit[14] ^ bit[11] ^ bit[10] ^ bit[ 9];
bit_out[ 7] = bit[15] ^ bit[12] ^ bit[11] ^ bit[10];
bit_out[ 8] = bit[ 0] ^ bit[13] ^ bit[12] ^ bit[11];
bit_out[ 9] = bit[ 1] ^ bit[14] ^ bit[13] ^ bit[12];
bit_out[10] = bit[ 2] ^ bit[15] ^ bit[14] ^ bit[13];
bit_out[11] = bit[ 3] ^ bit[15] ^ bit[14];
bit_out[12] = bit[ 4] ^ bit[15];
bit_out[13] = bit[ 5];
bit_out[14] = bit[ 6];
bit_out[15] = bit[ 7];
// 更新LFSR各个触发器的输出值
lfsr = 0;
for (i=0; i<16; i++)
{
lfsr += (bit_out[i] << i);
}
outbyte = 0;
for(i=0; i<8; i++)
{
outbyte += (descrambit[i] << i );
}
return outbyte;
}
python实现
# 8b/10b lfsr移动8次后输出D触发器D8-D15的结果
# D8 D9 D10 D11 D12 D13 D14 D15
# 1 1 1 1 1 1 1 1
# 0 0 0 1 0 1 1 1
# 1 1 0 0 0 0 0 0
# 0 0 0 1 0 1 0 0
def lsfr_output(array = []):
next_lfsr = [1,1,1,1,
1,1,1,1,
1,1,1,1,
1,1,1,1]
next_lfsr[0] = cur_lfsr[8]
next_lfsr[1] = cur_lfsr[9]
next_lfsr[2] = cur_lfsr[10]
next_lfsr[3] = cur_lfsr[11] ^ cur_lfsr[8]
next_lfsr[4] = cur_lfsr[12] ^ cur_lfsr[9] ^ cur_lfsr[8]
next_lfsr[5] = cur_lfsr[13] ^ cur_lfsr[10] ^ cur_lfsr[9] ^ cur_lfsr[8]
next_lfsr[6] = cur_lfsr[14] ^ cur_lfsr[11] ^ cur_lfsr[10] ^ cur_lfsr[9]
next_lfsr[7] = cur_lfsr[15] ^ cur_lfsr[12] ^ cur_lfsr[11] ^ cur_lfsr[10]
next_lfsr[8] = cur_lfsr[0] ^ cur_lfsr[13] ^ cur_lfsr[12] ^ cur_lfsr[11]
next_lfsr[9] = cur_lfsr[1] ^ cur_lfsr[14] ^ cur_lfsr[13] ^ cur_lfsr[12]
next_lfsr[10] = cur_lfsr[2] ^ cur_lfsr[15] ^ cur_lfsr[14] ^ cur_lfsr[13]
next_lfsr[11] = cur_lfsr[3] ^ cur_lfsr[15] ^ cur_lfsr[14]
next_lfsr[12] = cur_lfsr[4] ^ cur_lfsr[15]
next_lfsr[13] = cur_lfsr[5]
next_lfsr[14] = cur_lfsr[6]
next_lfsr[15] = cur_lfsr[7]
return next_lfsr
def xor(data,skip=0,lfsr=[],):
if skip:
print("data(hex) : " + data + " cur lfsr[8:15] : " + str(lfsr[8:]) + " skip de-scramble : " + data)
return
# note : 比如首先移动8次后, LFSR的输出为 0 0 0 1 0 1 1 1,其实指的是
# 正常流程 : 数据的bit[0]与LFRS D15的输出异或,然后移动一次,直到数据的bit[7]与D15触发器相异或
# 相当于LFSR移动8次 : bit[0]跟D7的输出相异或, bit[1]跟D8的输出相异或
binary_data = bin(int(str(data),16))[2:].zfill(8)
xor_out = [0,0,0,0,0,0,0,0]
for i in range(0,8):
xor_out[i] = int(binary_data[i]) ^ lfsr[i+8]
# 将列表转换为二进制字符串
binary_str = ''.join(str(x) for x in xor_out)
# 将二进制字符串转换为整数
decimal_value = int(binary_str, 2)
# 将整数转换为 16 进制数
hex_value = hex(decimal_value)[2:].upper()
print("data(hex) : " + data + " cur lfsr[8:15] : " + str(lfsr[8:]) + " de-scramble : " + hex_value)
# print(0x3a^lsfr_output(cur_lfsr)[8:15])
cur_lfsr = []
next_lfsr = []
init_lfsr = []
for i in range(0,15):
if i in [0,1,2]:
skip = 1
if i == 0:
data = 'COM'
init_lfsr = ['x','x','x','x','x','x','x','x','x','x','x','x','x','x','x','x']
xor(data,1,init_lfsr)
cur_lfsr = [1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1]
else:
data = 'PAD'
xor(data,1,cur_lfsr)
next_lfsr = lsfr_output(cur_lfsr)
cur_lfsr = next_lfsr
else:
if i == 3:
data = '3a'
elif i == 4:
data = '7e'
elif i == 80:
data = '7e'
else:
data = '4a'
xor(data,0,cur_lfsr)
next_lfsr = lsfr_output(cur_lfsr)
cur_lfsr = next_lfsr
perl实现,感谢@Alen的支持
#!/usr/bin/perl
use strict;
use warnings;
# 期望进行加扰的TS OS的16个symbol,此计算过程不包含对COM、PAD等特殊字符的处理,故前三位设置默认为0;
my @input_byte = (0x00,0x00,0x00,0x3a,0x7e,0x80,0x4a,0x4a,0x4a,0x4a,0x4a,0x4a,0x4a,0x4a,0x4a,0x4a);
# lsfr_value 此处用来声明初始的LSFR的值;
my $lsfr_value = 0xffff;
# 定义该数组,用来存放 lsfr_value 的各个bit位,便于后续的移位计算;
my @bits;
# 定义该数组,用来存放将要进行加扰data的各个bit位;
my @scramble_bit;
# 定义该变量,用来存放每次for循环中,正在进行加扰处理的数据(1symbol,8bit);
my $data;
# 定义该数组,用来临时存放每次移位8次后,lsfr的各个bit位的值的变化;
my @bit_out;
# 定义该变量,用来存放加扰后需要输出的数据;
my $outbyte;
for(my $j=1; $j<16 ;$j++){
$data = $input_byte[$j];
# Convert LFSR output to array.
for my $i (0..15){
$bits[$i] = ($lsfr_value >> $i) & 1;
}
# Convert input_byte to array.
for my $i (0..7){
$scramble_bit[$i] = ($data >> $i) & 1;
}
# Scrambling!!!
if(1){
$scramble_bit[0] ^= $bits[15];
$scramble_bit[1] ^= $bits[14];
$scramble_bit[2] ^= $bits[13];
$scramble_bit[3] ^= $bits[12];
$scramble_bit[4] ^= $bits[11];
$scramble_bit[5] ^= $bits[10];
$scramble_bit[6] ^= $bits[9];
$scramble_bit[7] ^= $bits[8];
}
# Shift LFSR bits by 8 times
@bit_out = (
$bits[8],
$bits[9],
$bits[10],
$bits[11] ^ $bits[8],
$bits[12] ^ $bits[9] ^ $bits[8],
$bits[13] ^ $bits[10] ^ $bits[9] ^ $bits[8],
$bits[14] ^ $bits[11] ^ $bits[10] ^ $bits[9],
$bits[15] ^ $bits[12] ^ $bits[11] ^ $bits[10],
$bits[0] ^ $bits[13] ^ $bits[12] ^ $bits[11],
$bits[1] ^ $bits[14] ^ $bits[13] ^ $bits[12],
$bits[2] ^ $bits[15] ^ $bits[14] ^ $bits[13],
$bits[3] ^ $bits[15] ^ $bits[14],
$bits[4] ^ $bits[15],
$bits[5],
$bits[6],
$bits[7]
);
# Update LFSR value.
$lsfr_value = 0;
for my $i (0..15){
$lsfr_value += ($bit_out[$i] << $i);
}
# Update Scrambled data value.
$outbyte = 0;
for my $i (0..7){
$outbyte += ($scramble_bit[$i] << $i);
}
printf "The symbol %d th after scramble data value is:%x .\n ",$j,$outbyte;
}
数据serialization(串行化)和De-serialization(解串行化)
串行化就是将并行数据转换为串行数据,然后通过差分信号传输出去。在串行化之前,需要经过加扰和8b/10b编码,原始数据的bit[7:0]表示为HGFEDCBA,额外用一比特Z表示是否属于控制码,经过8b/10b编码后,bit[9:0]为jhgfiedcba。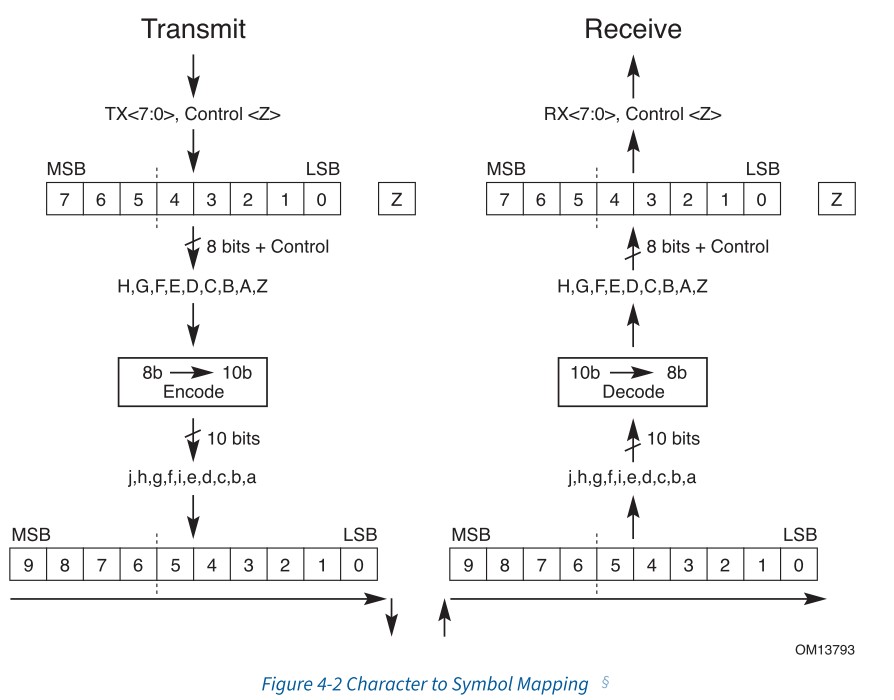
pcie采用的是小端模式,即先传低位然后再传高位。8b/10b编码中一个symbol在差分线上是10个比特。
下图是链路为x1时,传输OS的例子,由于是小端模式,最开始传输的是最低位a,最后传输的是最高位j。传输完一个symbol的时间就是symbol time,传输完一个比特的时间就是Unit Interval(单元间隔,简称UI)。在2.5GT/s的串行速率下,symbol time计算如下:2.5GT/s速率,一秒可以传输2.5GT比特数据,传输1比特数据的时间为1×109/(2.5×109)=0.4ns,由于8b/10b编码中,差分线上的一个symbol为10比特。所以2.5GT/s下,一个UI为0.4ns,一个symbol time就是0.4ns×10=4ns。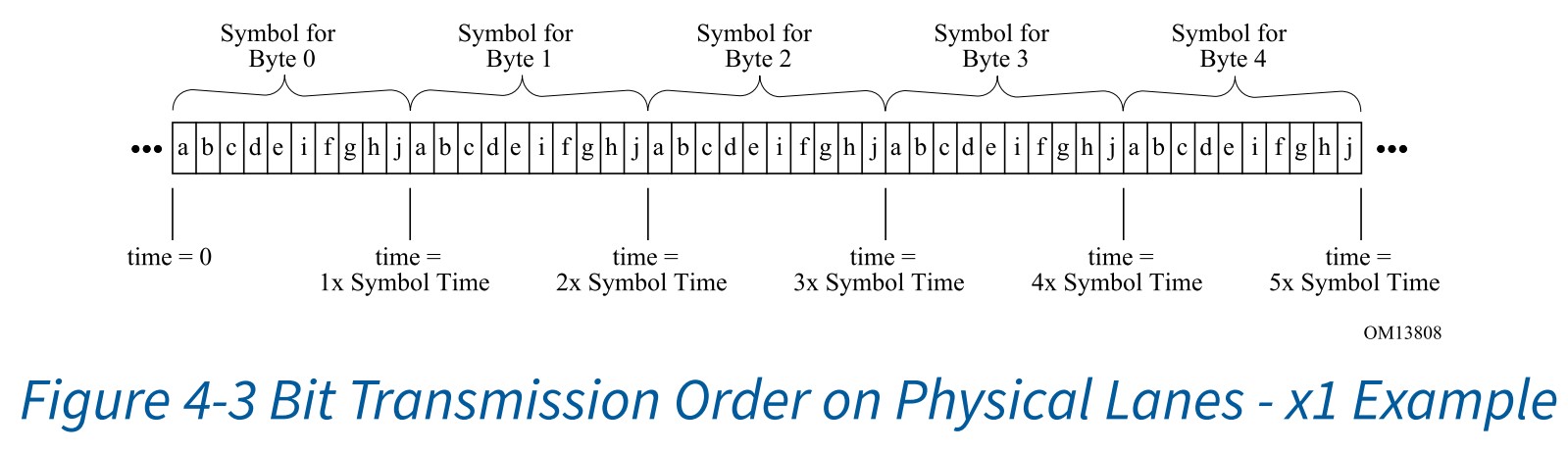
下图是链路宽度为x4时,传输OS的例子,与x1传输基本一致,只是在多lane的link上,需要在所有lane上同时传输OS。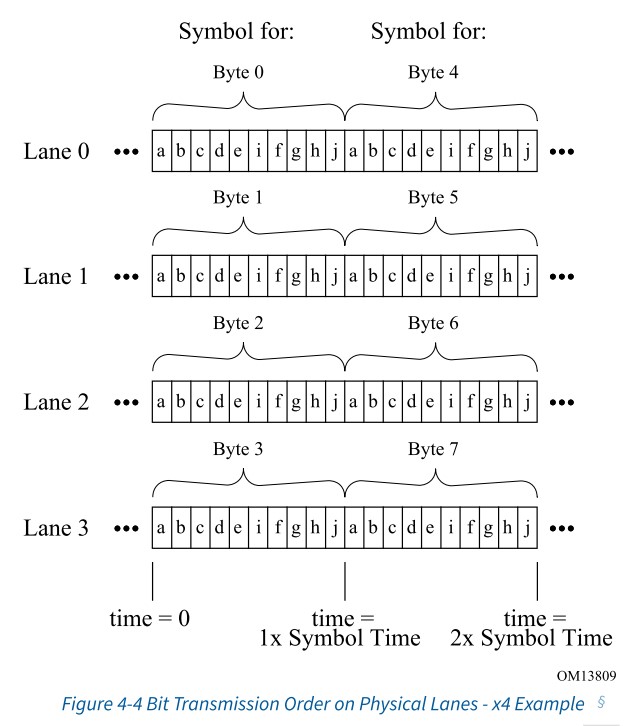
你好,請問 8b/10b 和 Scrambler 的功能是不是類似的?
為什麼需要同時做這2種功能呢?
Gen3 之後只使用 Scrambler, 是否說明 8b/10b 不是很有必要呢?
剛開始讀 pci,對此很困惑😖
@seruze 你好 ,
請問 8b/10b 和 Scrambler 的功能是不是類似的?
编码和加绕还是不一样的,8b/10b编码的主要功能是保持直流平衡,因为经过8b/10b编码后的数据0和1的个数比较接近,不会出现长0或长1的情况,出现长0或者长1可能会导致接收端对电平0,1的识别出现误判,而加绕主要是防止不同lane之间的干扰,比如一个x16的链路,在发相同的有续集(order set)时,如果没有加绕,这16条lane发送的数据就是一样的,更容易产生干扰,加饶之后,每条lane传输的数据就变得伪随机了,可以降低lane与lane之间的干扰。所以在tx方向,一般都是先加绕,然后进行8b/10b编码。补充:一条lane也是可以降低干扰的,这也比较好理解,如果不加扰,一条lane传输的内容完全一样,就相当于是形成了高频信号,容易受到外界或者内部干扰。
為什麼需要同時做這2種功能呢?
因为它们的作用是不一样的
Gen3 之後只使用 Scrambler, 是否說明 8b/10b 不是很有必要呢?
gen3-gen5没有采用8b/10b编码是因为8b/10b编码的效率比较低,一个8比特的数需要10比特来编码,这样在传输时会浪费到20%的带宽,对gen3以上的速率来讲,浪费太多,可能不太容易接受,所以gen3-gen5 换了更高效的编码128b/130b编码,128b/130b编码从编码方式来讲并不能维持直流平衡,所以协议换了一种加绕算法来让0,1的个数稍微平衡点,此外,为了维持0,1个数平衡,协议在很多地方都有做专门的处理,比如TS1,TS2的symbol 14-15就可以根据前面0,1个数的差别来看是作为TS的标识符还是作为直流平衡用。gen3很多有续集的定义0,1的个数基本是相等的,而且有续集通常还不需要加绕,也都是维持直流平衡。在链路训练过程中,两端交换最对的就是TS,所以为了在128b/130b编码中,对TS的很多symbol也都是进行了加绕处理,防止lane与lane之间的干扰,而在8b/10b编码下,TS没有加绕的,但是在8b/10b编码下,一定程度上也可以防止lane与lane之间的干扰,因为8b/10b编码会根据当前运行一致性(就是0,1个数的差别)来确定编码后的值,在多lane的链路上,一定程度上也可以保证每条lane传输的内容不一样
@重新开始 真是很感謝您這麼詳細的回應,我會再好好研讀這方面的資料,再次感謝您的回答,也希望您能繼續推出 pcie 的文章分享,真的很受用,謝謝:)
翻译的很准确易懂,加扰那我想请教一下。8b/10b的加扰码循环的时候是类似D3<= D15 ^ D2这么循环的是么,加扰码只和自身的循环时间有关?
之前只接触过以太网的自同步加扰,pcie这个加扰感觉对两边的comma检测要求很严啊,错一点就一直对不上了
@Nephalem郑 数据的D3相当于是LFSR的D12异或,第一个时钟周期时,LFSR的D15跟数据的D0异或输出,下一个时钟周期,LFSR的D15就是上一个时钟周期D14的值了,同样数据的D0是上一个周期的D1,所以D1是跟D14异或,同理,数据D3是跟LFSR的D12异或。所以也可以做成在同一周期,数据的bit[0:7]与LFSR的bit[15:8]异或。然后下一个symbol来时,LFSR的输出变为D7-D0经过一番逻辑之后的值了。来一个symbol,LFSR就移动一次。这个只是针对gen1/2,因为gen1/2 LFSR的D8-D14没有经过任何组合逻辑,只是单纯的移位。
LFSR的输出D15-D8是每来一个symbol,整体变化一次,比如第一个symbol为COM字符,COM不加绕,LFSR的输出D15-D0全变为1,然后下一个symbol到来时,LFSR内部就开始移位和一些异或操作,其输出为xxxx,数据跟D15-D8按位异或(但是此时的D15-D8已经是D7-D0经过组合逻辑之后的结果了,不再是ff)。你说的加绕码是指LFSR的输出吗?如果是这样的话,那确实是只跟时间有关,因为LFSR的初始值确定好之后,后面所有的数都是确定的,所以叫伪随机数。
错一点就对不上是指啥呢?
pcie对COM的检测确实比较严,如果发送端COM有误,那么就不会初始化LFSR了,如果在链路上没有发生错误,对端收到的数据还是很本端发送的数据一样。
如果本端发送的数据无误,是链路上发生了错误,比如把COM 8b/10b编码后的某一比特给弄错了,这时会发生8b/10b decode error,对端也无法识别这个COM字符了,后面的数据自然也都是错的数。但是本端是在一直发TS的,如果对端一直没收到正确的COM,那就是链路质量太差了,这种情况无法训练也是合理的。
我说的不太清楚,我说的D3<= D15 ^ D2都是指的LSFR的寄存器,我是想说LFSR寄存器移位的时候下一时刻的D3/D4/D5是不是都是前一个数据和D15异或来的?我看图里好像是这个意思。
按照我对以太网的加扰公式的理解,G(X)=X16+X5+X4+X3+1应该指的是G(X)是LSPR寄存器的[15]/[4]/[3]/[2]/[0]相互异或得出的,而G(X)和当前数据bit异或得出当前bit的加扰后数据
错一点就对不上我是指比如comma检测的不同步或者底层传输数据整体串了,比如提前或者滞后1bit什么的,后面的解扰就会全错,不过我仔细想了想应该不会出现这种问题,真出现了肯定会有各种报错
@Nephalem郑 懂了,你说的自同步加扰就是External Feedback LFSR,PCIE用的是第二种Internal Feedback LFSR(这种可以做到更高的频率)。这两种LFSR的多项式都是一样的,PCIE用的LFSR下一个时刻的D3/D4/D5就是前一个数据和D15异或而来的。